- 帖子
- 176
- 精华
- 1
- 积分
- 733
- 阅读权限
- 100
- 注册时间
- 2013-8-21
- 最后登录
- 2020-12-20
  
|
每个英语学渣(好吧,其实这个说的就是学渣本渣了♀)都有这样一个梦想:能够一边轻松愉快地看着美剧,一边自己的英语听力水平还能蹭蹭地往上涨。知乎上也有很多人分享了自己通过美剧练习听力的方法,比如说只开英文字幕或者干脆就不要字幕。但是这两个方法都有自己的缺点,只开英文字幕的方法虽然说避免了下意识只看中文,但是却造成了只看字幕不听读音,从而练习了阅读忽略了听力;不开字幕的方法确实做到了强迫自己必须认真听,可是对于很多人来说,美剧中充满了大量的陌生词汇,比如说:

这句话中的 betrayal 是背叛的名词形式,可能很多人就不认识,或者说认识但是却没听过他的正确发音。这样一来,对这句话的理解就会出现障碍。美剧中还有很多类似情况,用这样的听力材料显然是不适合的。为了应对这种情况,我有了个想法:将字幕中的词汇拆分,并进行词频的检测,如果词频在 4000(可以根据自己的情况进行调整)以内,则将单词删除,如果词频在 4000 以外,则单独标注出该词的中文,效果如下:

这样一来,这句话对于我来说就没有任何词汇上的障碍,假如一遍听不懂,我就可以放心大胆的再听一遍而不必担心是由于词汇的问题造成的理解障碍。
下面介绍程序的大体思路:
首先观察字幕文件,选择后缀名为 srt 的字幕文件用记事本打开如下(其他类型的字幕文件用记事本打开以后格式非常复杂,此处不讨论):
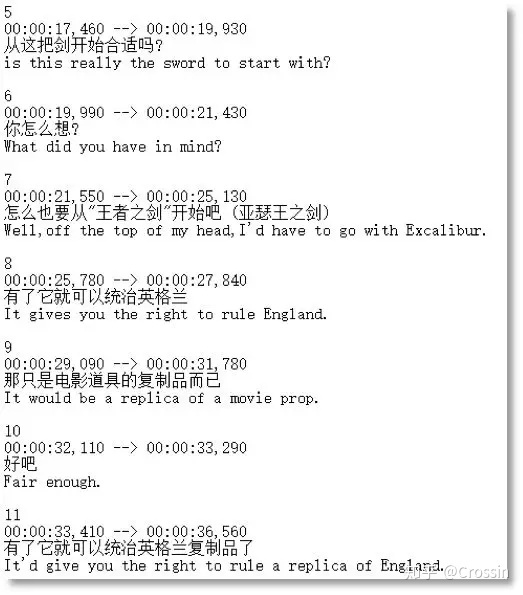
观察文本特点,撰写相应的正则表达式。
虽然在 Python 中使用正则表达式有几个步骤,但每一步都相当简单。
用import re导入正则表达式模块。用re.compile()函数创建一个Regex对象(记得使用原始字符串)。向Regex对象的search()方法传入想查找的字符串。它返回一个Match对象。调用Match对象的group()方法,返回实际匹配文本的字符串。
常用的匹配规则:
?匹配零次或一次前面的分组。*匹配零次或多次前面的分组。+匹配一次或多次前面的分组。{n}匹配 n 次前面的分组。{n,}匹配 n 次或更多前面的分组。{,m}匹配零次到 m 次前面的分组。{n,m}匹配至少 n 次、至多 m 次前面的分组。{n,m}?或*?或+?对前面的分组进行非贪心匹配。^spam意味着字符串必须以 spam 开始。spam$意味着字符串必须以 spam 结束。.匹配所有字符,换行符除外。\d、\w和\s分别匹配数字、单词和空格。\D、\W和\S分别匹配出数字、单词和空格之外的所有字符。[abc]匹配方括号内的任意字符(诸如 a、b 或 c)。[^abc]匹配不在方括号内的任意字符
Python中转义字符使用倒斜杠(\)。字符串'\n'表示一个换行字符,而不是倒斜杠加上一个小写的n。你需要输入转义字符\\,才能打印出一个倒斜杠。所以'\\n'表示一个倒斜杠加上一个小写的 n。但是,通过在字符串的第一个引号之前加上r,可以将该字符串标记为原始字符串,它不包括转义字符。输入r'\d\d\d-\d\d\d-\d\d\d\d',比输入'\\d\\d\\d-\\d\\d\\d-\\d\\d\\d\\d'要容易得多。
由上述相应规则结合文本特点得到:- #空行、行数标号正则表达式
- rgx_none_and_num = re.compile(r'\d{1,2}\n')
- #时间正则表达式
- rgx_time = re.compile(r'\d\d:\d\d:\d\d,\d\d\d --> \d\d:\d\d:\d\d,\d\d\d\n')
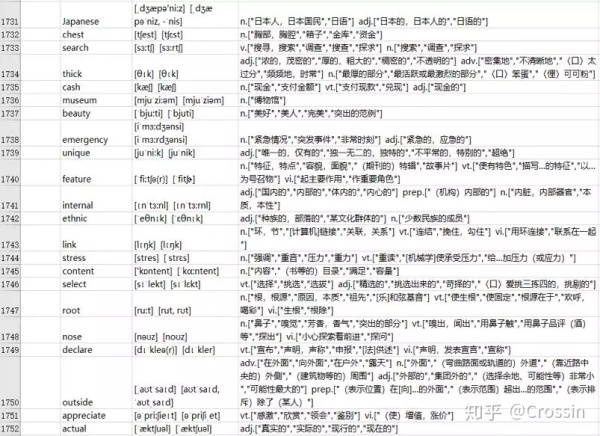
要处理表格,需要用到 openpyxl 模块,下面是从电子表格文件中读取单元格涉及的所有函数、方法和数据类型。
导入openpyxl模块。调用openpyxl.load_workbook()函数。取得Workbook对象。调用get_active_sheet()或get_sheet_by_name()工作簿方法。取得Worksheet对象。使用索引或工作表的cell()方法,带上row和column关键字参数。取得Cell对象。读取Cell对象的value属性。
由上述结合表格内容,建立词库字典:- #词频在4000以后的字典:
- wordlist4001 = {}
- #事先将名为“1-20000.xlsx”的词频表放在当前工作目录
- excel_content = openpyxl.load_workbook('1-20000.xlsx')
- sheet = excel_content['Sheet1']
- for row in range(4000,20201):
- wordlist4001[sheet.cell(row,1).value] = sheet.cell(row,2).value
- #词频在4000以前的字典:
- wordlist4000 = {}
- for row in range(1,4001):
- wordlist4000[sheet.cell(row,1).value] = sheet.cell(row,2).value
- # -*- coding:utf-8 -*-
- #导入模块
- import re,openpyxl
- #读入字幕文件
- text=open('The.Big.Bang.Theory.s05e05.720p.x264.chs&eng.srt','r')
- #空行、行数标号正则表达式
- rgx_none_and_num = re.compile(r'\d{1,2}\n')
- #时间正则表达式
- rgx_time = re.compile(r'\d\d:\d\d:\d\d,\d\d\d --> \d\d:\d\d:\d\d,\d\d\d\n')
- #处理字幕文件
- first_step = text.readlines()
- #新建一个字幕文件
- new_file = open('C:\\Users\\SYQ\Desktop\\处理版.srt','w')
- #建立4000后的字典
- wordlist4001 = {}
- excel_content = openpyxl.load_workbook('1-20000.xlsx')
- sheet = excel_content['Sheet1']
- for row in range(4000,20201):
- wordlist4001[sheet.cell(row,1).value] = sheet.cell(row,2).value
- #建立4000前的字典
- wordlist4000 = {}
- for row in range(1,4001):
- wordlist4000[sheet.cell(row,1).value] = sheet.cell(row,2).value
- #挑选出文字行进行处理
- for line in first_step:
- #如果为空行,行数标号,则不动
- if rgx_none_and_num.search(line):
- new_file.write(line)
- #如果为时间行则不动
- elif rgx_time.search(line):
- new_file.write(line)
- #如果为字幕行,则处理
- else:
- words = line.lower().split()
- for word in words:
- #如果单词不在字典中,则跳过
- if word in wordlist4000:
- pass
- #如果单词在字典中,则添加翻译
- elif word not in wordlist4001:
- pass
- else:
- new_word = word + ':' + wordlist4001[word] +'\n'
- new_file.write(new_word)
- #关闭文件
- text.close()
- new_file.close()
----------
本文是我们编程教室新春征稿活动的一篇投稿,来自作者 @司夜。他和我们很多读者一样,学习 python 的时间并不长,但已经把 python 应用到自己的日常学习生活中,并整理成文投稿给我们,这很值得肯定。在实践中应用和向他人讲解都是非常好的学习方式。不用在意自己写的代码还不够完善,Done is better than perfect!我们编程教室会持续向所有人开放,如果有投稿或参与志愿者的意向,欢迎随时在公众号里给我们留言。另外,关于编程与英语的结合,我们之前也有过不少文章,感兴趣的可以阅读:Crossin:我们用程序整理出了一份Python英语高频词汇表,拿走不谢!分享一个强大的英汉词典开源数据库英语 vs 编程【每周一坑】单词本(此系列可在公众号“每周一坑”栏目中查看)
════
其他文章及回答:
学编程:如何自学Python | 新手引导 | 一图学Python
开发案例:智能防挡弹幕 | 红包提醒 | 流浪地球
欢迎搜索及关注:Crossin的编程教室
 |
|



 |手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 )
|手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 ) 





 发表于 2019-2-28 22:29:53
发表于 2019-2-28 22:29:53
 收藏
收藏