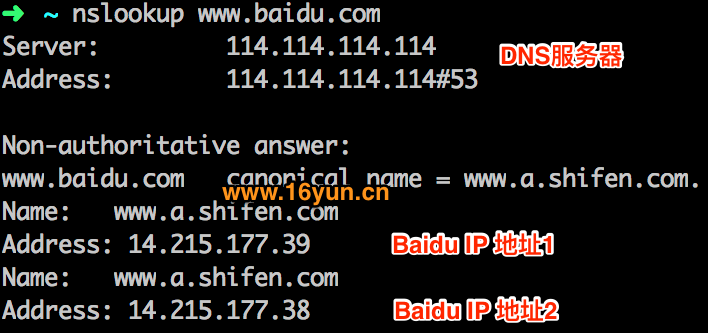
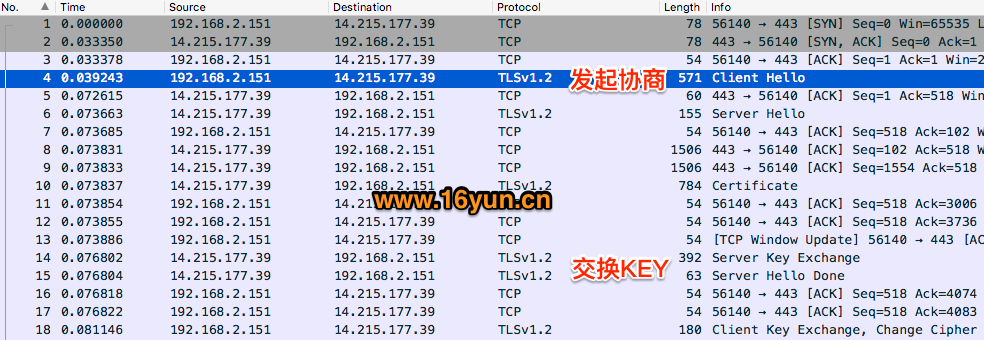
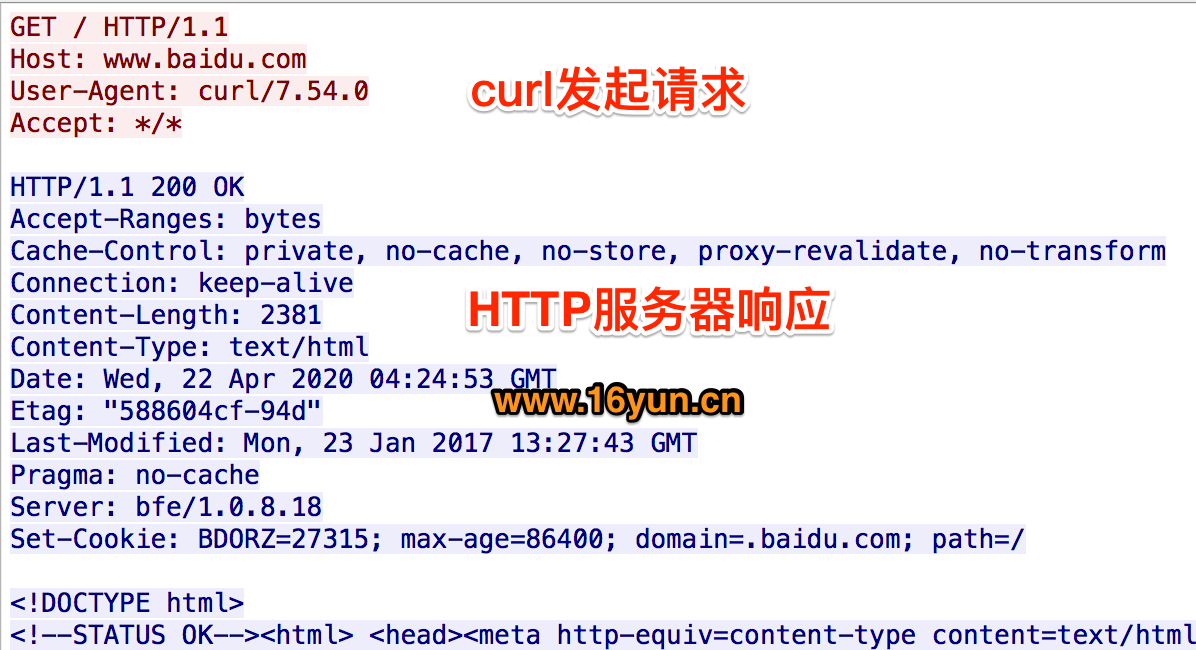
当我们在浏览器中输入URL后,会发生什么?比如https://www.baidu.com 1、查找域名对应的IP地址 我们可以通过nslookup www.baidu.com模拟这个过程,dns服务器返回两个IP地址,curl会随机选用其中一个IP服务器进行访问。 2、向IP对应的服务器发送SSL协商请求,进行SSL协商 下图是通过Wireshark抓包获取的协商过程。 3、SSL协商完成后,向IP对应服务器发起GET请求 > GET / HTTP/1.1 > User-Agent: curl/7.54.0 网站会检查是不是真的浏览器访问。需加上User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.1276.73 Safari/537.36,表明你是浏览器访问即可。有时还会检查是否带Referer信息还会检查你的Referer是否合法。
4、服务器响应请求,发回网页内容 < HTTP/1.1 200 OK < Connection: keep-alive
< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/ < <!DOCTYPE html>...</html>
服务器一般会使用cookie来标识用户,如果接受并带上该cookie继续访问,服务器会认为你是一个已标识的正常用户。因此,大部分网站需要使用cookie的来爬取内容。
| 


 |手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 )
|手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 ) 





 发表于 2020-5-7 17:49:33
发表于 2020-5-7 17:49:33
 收藏
收藏