Crossin的编程教室
标题: 加速数据采集的措施 [打印本页]
作者: yiniuyun0 时间: 2020-6-24 16:46
标题: 加速数据采集的措施
当爬取的数据量非常大时,如何高效快速地进行数据抓取是关键。
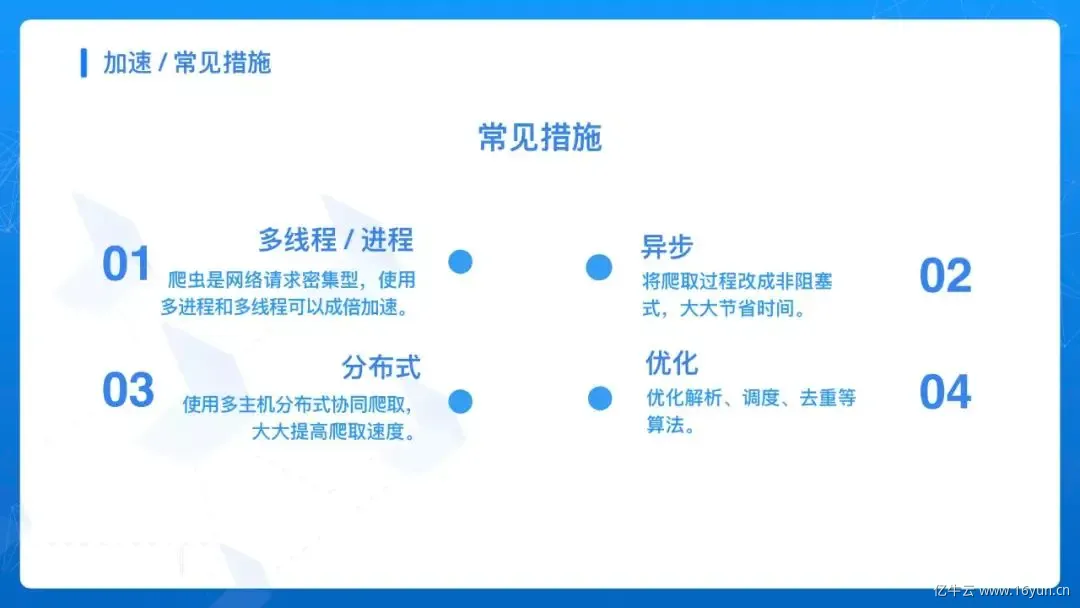
常见的措施有多线程、多进程、异步、分布式、细节优化等。
加速 / 多线程、多进程爬虫是网络请求密集型任务,所以使用多进程和多线程可以大大提高抓取效率,如使用 threading、multiprocessing 等。
加速 / 异步将爬取过程改成非阻塞形式,当有响应式再进行处理,否则在等待时间内可以运行其他任务,如使用 asyncio、aiohttp、Tornado、Twisted、gevent、grequests、pyppeteer、pyspider、Scrapy 等。
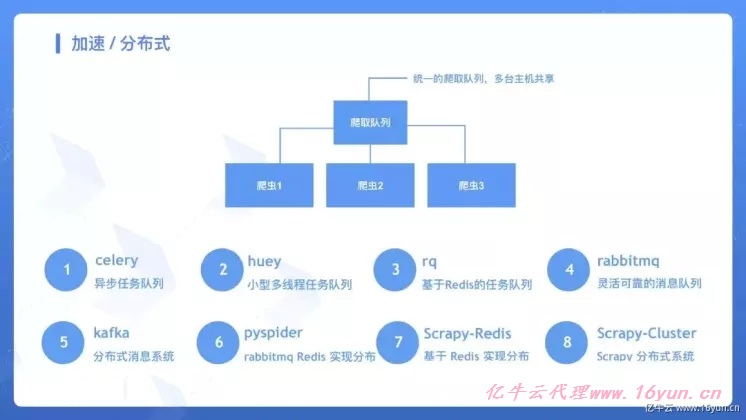
加速 / 分布式分布式的关键在于共享爬取队列,可以使用 celery、huey、rq、rabbitmq、kafka 等来实现任务队列的对接,也可以使用现成的框架 pyspider、Scrapy-Redis、Scrapy-Cluster 等。
加速 / 优化可以采取某些优化措施来实现爬取的加速,如:
- DNS 缓存
- 使用更快的解析方法
- 使用更高效的去重方法
- 模块分离化管控
加速 / 架构如果搭建了分布式,要实现高效的爬取和管理调度、监控等操作,我们可以使用两种架构来维护我们的爬虫项目。
- 将 Scrapy 项目打包为 Docker 镜像,使用 K8S 控制调度过程。
- 将 Scrapy 项目部署到 Scrapyd,使用专用的管理工具如 SpiderKeeper、Gerapy 等管理。
| 欢迎光临 Crossin的编程教室 (https://bbs.crossincode.com/) |
Powered by Discuz! X2.5 |