|
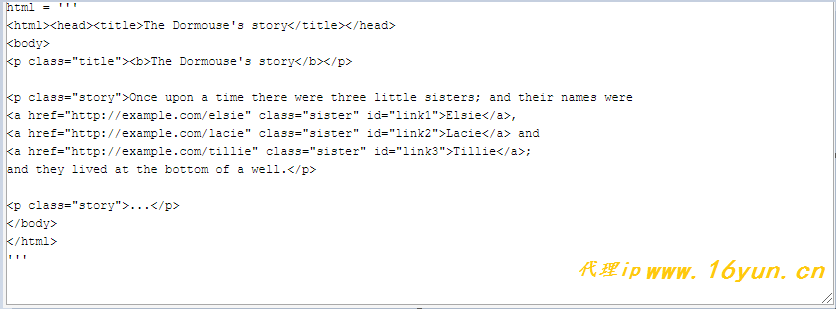
数据采集的最终的目的就是过滤选取网络信息,因此最重要的部分就是解析了,数据解析的优劣决定了网络爬虫的速度和效率,对于 HTML 类型的页面来说,常用的解析方法其实无非那么几种,正则、XPath、CSS Selector,另外对于某些接口,常见的可能就是 JSON、XML 类型,使用对应的库进行处理即可。这里重点讲述的是XPath。 XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。 数据解析之前需要先将html代码转换成相应的对象,方法如下 In [7]: from lxml import etree In [8]: text = etree.HTML(html) 示例1 接下来我们来用不同的解析方法分析示例的HTML代码 In [16]: text.xpath('//title/text()')[0] Out[16]: "The Dormouse's story" 个人觉得lxml在解析HTML时还是很简洁好用的。而且lxml是使用XPath这种文本语法而非函数API,写起来更轻量化,只要会XPath语法就可以轻松解析HTML。这就好比在处理复杂的文本时,使用正则表达式比使用字符串类的函数API更好用、更强大。
| 


 |手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 )
|手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 ) 





 发表于 2020-5-14 17:29:23
发表于 2020-5-14 17:29:23
 收藏
收藏