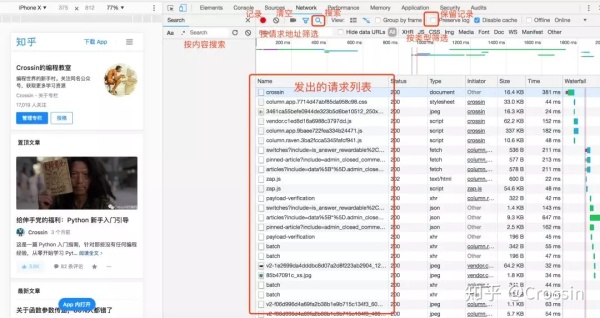
并不是所有 URL 都能直接通过 GET 获取(相当于在浏览器里打开地址),通常还要考虑这几样东西:
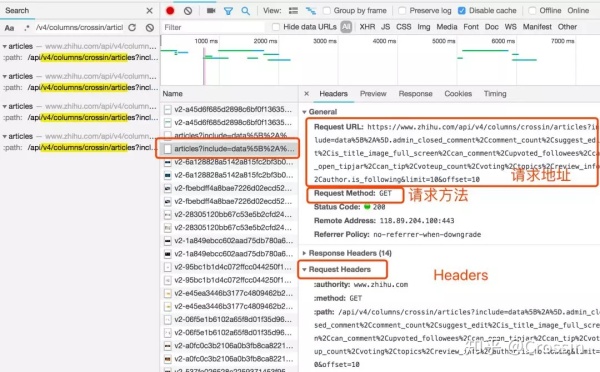
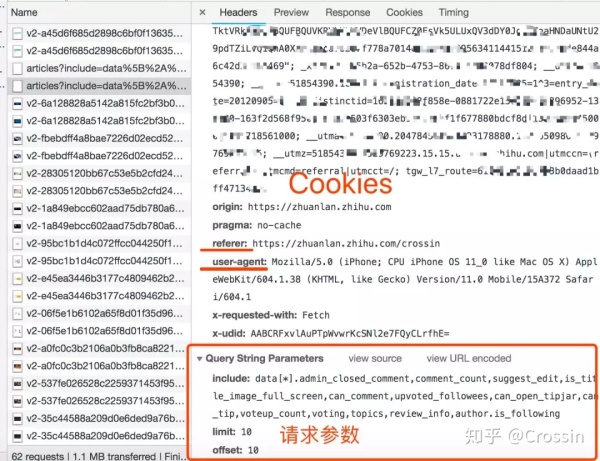
请求方法,是 GET 还是 POST。请求附带的参数数据。GET 和 POST 传递参数的方法不一样。Headers 信息。常用的包括 user-agent、host、referer、cookie 等。其中 cookie 是用来识别请求者身份的关键信息,对于需要登录的网站,这个值少不了。而另外几项,也经常会被网站用来识别请求的合法性。同样的请求,浏览器里可以,程序里不行,多半就是 Headers 信息不正确。你可以从 Chrome 上把这些信息照搬到程序里,以此绕过对方的限制。
点击列表中的一个具体请求,上述信息都可以找到。
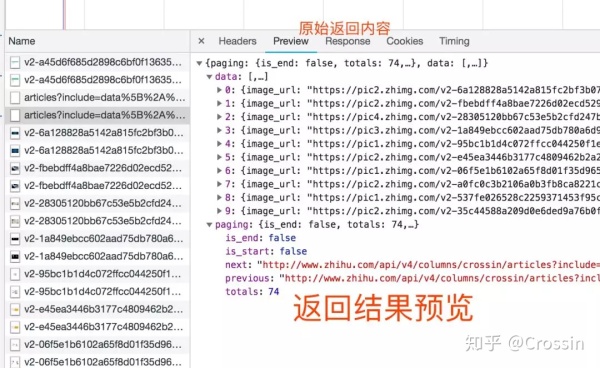
找对请求,设对方法,传对参数以及 Headers 信息,大部分的网站上的信息都可以搞定了。
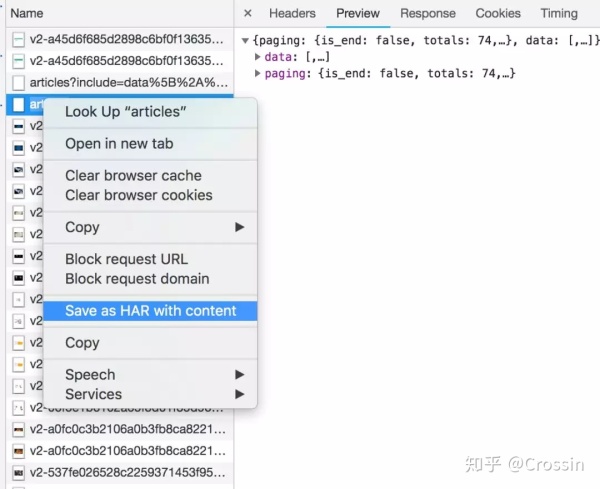
Network 还有个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。这个文件包含了列表中所有请求的各项参数及返回值信息,以便你查找分析。(实际操作中,我发现经常有直接搜索无效的情况,只能保存到文件后搜索)
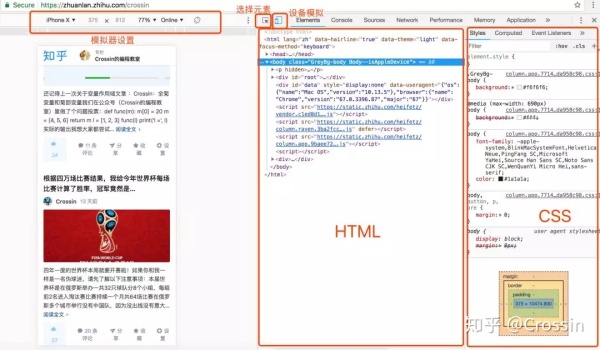
除了 Elements 和 Network,开发者工具中还有一些功能,比如:



 |手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 )
|手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 ) 








 发表于 2018-7-9 18:09:54
发表于 2018-7-9 18:09:54

 收藏
收藏