|
9175| 2
|



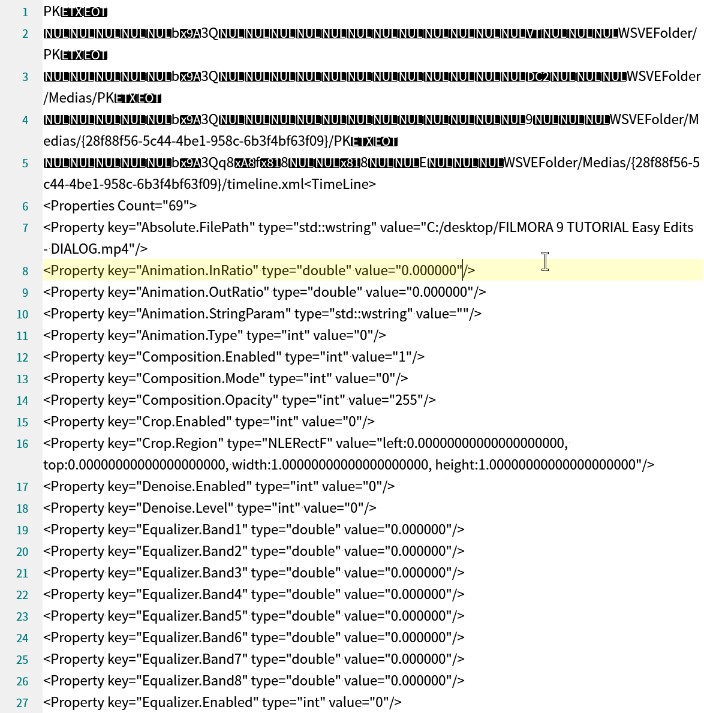
如何读取机器码和文本混合的文档,从中提取文本部分的内容? |
|
|
| |
|
|
| |
|
#==== Crossin的编程教室 ====#
微信ID:crossincode 网站:http://crossincode.com |
||
|
|
| |
 |手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 )
|手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 ) 
GMT+8, 2024-11-23 17:42 , Processed in 0.025177 second(s), 24 queries .
Powered by Discuz! X2.5
© 2001-2012 Comsenz Inc.





 发表于 2020-9-20 03:17:25
发表于 2020-9-20 03:17:25


 收藏
收藏

 发表于 2020-9-20 15:47:54
发表于 2020-9-20 15:47:54
