|
9692| 3
|



爬虫+网站开发实例:电影票比价网 |
|
|
| |
|
|
| |
|
#==== Crossin的编程教室 ====#
微信ID:crossincode 网站:http://crossincode.com |
||
 |手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 )
|手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 ) 
GMT+8, 2024-11-21 20:34 , Processed in 0.015838 second(s), 23 queries .
Powered by Discuz! X2.5
© 2001-2012 Comsenz Inc.








 发表于 2019-3-7 11:46:21
发表于 2019-3-7 11:46:21
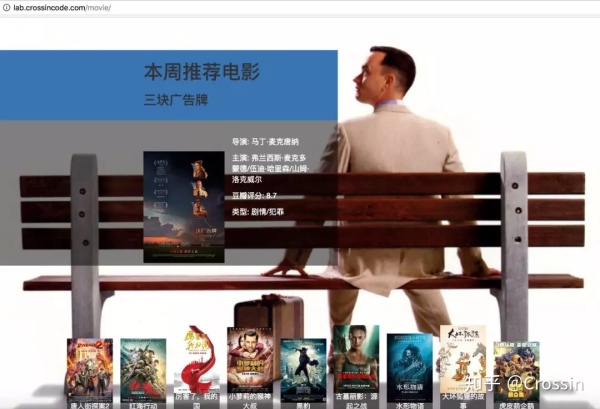
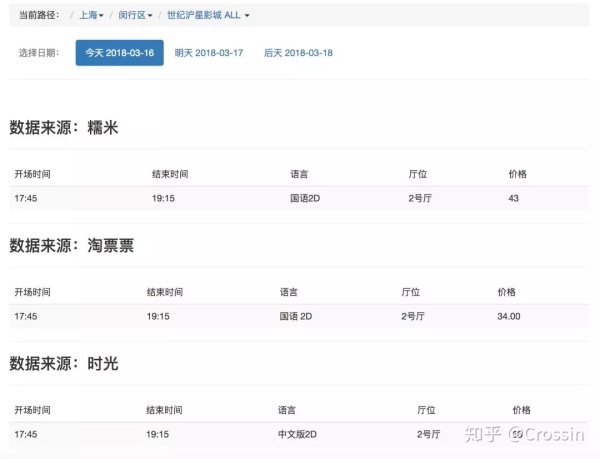 实现技术
实现技术
 收藏
收藏 发表于 2019-6-6 13:38:30
发表于 2019-6-6 13:38:30

 发表于 2019-6-21 15:32:28
发表于 2019-6-21 15:32:28
