Crossin的编程教室
标题:
用Python分析公开数据选出高送转预期股票
[打印本页]
作者:
江水滔滔
时间:
2018-7-3 19:10
标题:
用Python分析公开数据选出高送转预期股票
本文授权转载自公众号:挖地兔(waditu)- Jimmy米哥
上周五,永和智控公布了高送转预案,开盘涨停并直至收盘,打响了2016年报高送转的第一枪,一些具备高送转预期的个股也纷纷上涨,再次启动了高送转行情。
根据以往的经验,每年年底都会有一波高送转预期行情。今天,米哥就带大家实践一下如何利用tushare实现高送转预期选股。
本文主要是讲述选股的思路方法,选股条件和参数大家可以根据米哥提供的代码自行修改。
1. 选股原理
一般来说,具备高送转预期的个股,都具有总市值低、每股公积金高、每股收益大,流通股本少的特点。当然,也还有其它的因素,比如当前股价、经营收益变动情况、以及以往分红送股习惯等等。
这里我们暂时只考虑每股公积金、每股收益、流通股本和总市值四个因素,将公积金大于等于5元,每股收益大于等于5毛,流通股本在3亿以下,总市值在100亿以内作为高送转预期目标(这些参数大家可根据自己的经验随意调整)。
2. 数据准备
首先要导入tushare:
import tushare as ts
复制代码
调取股票基本面数据和行情数据
# 基本面数据
basic = ts.get_stock_basics()
# 行情和市值数据
hq = ts.get_today_all()
复制代码
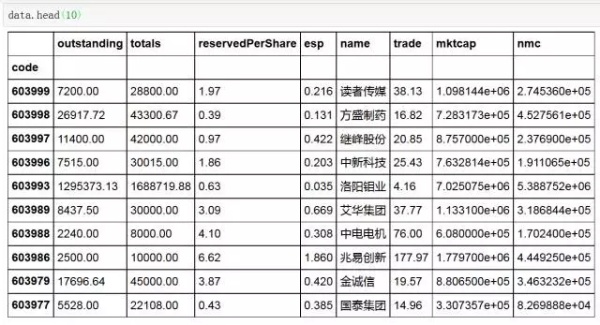
3. 数据清洗整理
对获取到的数据进行清洗和整理,只保留需要的字段。(其它字段及含义,请参考
http://tushare.org
文档)
#当前股价,如果停牌则设置当前价格为上一个交易日股价
hq['trade'] = hq.apply(lambda x:x.settlement if x.trade==0 else x.trade, axis=1)
#分别选取流通股本,总股本,每股公积金,每股收益
basedata = basic[['outstanding', 'totals', 'reservedPerShare', 'esp']]
#选取股票代码,名称,当前价格,总市值,流通市值
hqdata = hq[['code', 'name', 'trade', 'mktcap', 'nmc']]
#设置行情数据code为index列
hqdata = hqdata.set_index('code')
#合并两个数据表
data = basedata.merge(hqdata, left_index=True, right_index=True)
复制代码
4. 选股条件
根据上文提到的选股参数和条件,我们对数据进一步处理。
将总市值和流通市值换成亿元单位
data['mktcap'] = data['mktcap'] / 10000
data['nmc'] = data['nmc'] / 10000
复制代码
设置参数和过滤值(此次各自调整)
#每股公积金>=5
res = data.reservedPerShare >= 5
#流通股本<=3亿
out = data.outstanding <= 30000
#每股收益>=5毛
eps = data.esp >= 0.5
#总市值<100亿
mktcap = data.mktcap <= 100
复制代码
取并集结果:
allcrit = res & out & eps & mktcap
selected = data[allcrit]
复制代码
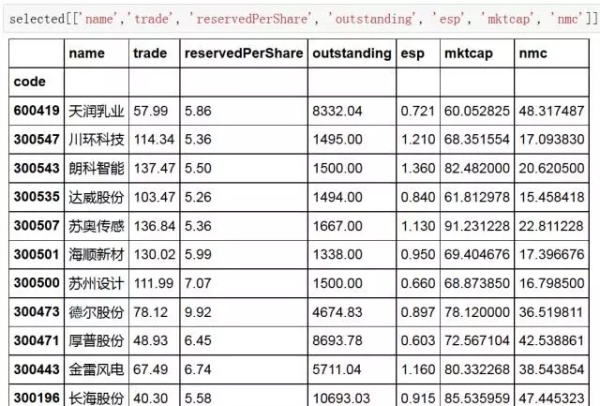
具有高送转预期股票的结果呈现:
以上字段的含义分别为:股票名称、收盘价格、每股公积金、流通股本、每股收益(应该为eps,之前发布笔误)、总市值和流通市值。
(本文仅作为编写选股策略的实例练习,不构成任何投资参考建议。投资有风险,入市需谨慎。)
在公众号(crossincode)中回复『高送转』,可以查看完整示例代码。
对数据分析和量化感兴趣的朋友,可关注公众号 “挖地兔”(waditu),阅读更多相关文章。
欢迎光临 Crossin的编程教室 (https://bbs.crossincode.com/)
Powered by Discuz! X2.5