Crossin的编程教室
标题:
这个男人让你的爬虫开发效率提升8倍
[打印本页]
作者:
江水滔滔
时间:
2018-6-28 15:39
标题:
这个男人让你的爬虫开发效率提升8倍
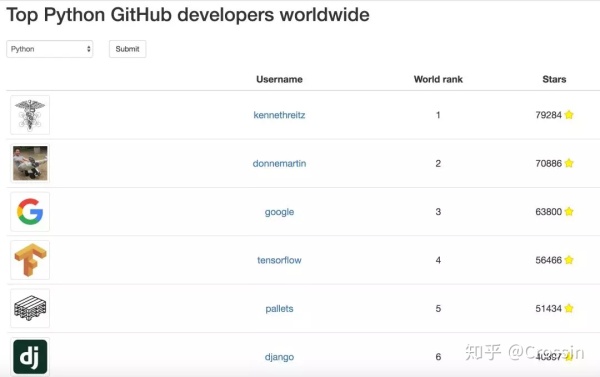
他叫 Kenneth Reitz。现就职于知名云服务提供商 DigitalOcean,曾是云计算平台 Heroku 的 Python 架构师,目前 Github 上 Python 排行榜第一的用户。(star 数超过了包括 google、tensorflow、django 等账号)
但他被更多路人所熟知的,恐怕还是他从一名技术肥宅逆袭成为文艺高富帅的励志故事:
看看他的个人主页
www.kennethreitz.org
上的标签:
除了程序员,还有摄影师、音乐家、演讲者……不怪在社交媒体上被称为“程序员届的网红”。
然而,作为一个严肃的技术号,今天我们不是要八卦他的开挂人生,而是他的代表作品:Requests
(如果你还是想看八卦,给你个传送门:
谁说程序员不是潜力股?让这位世界前五名的天才程序员来颠覆你三观!
)
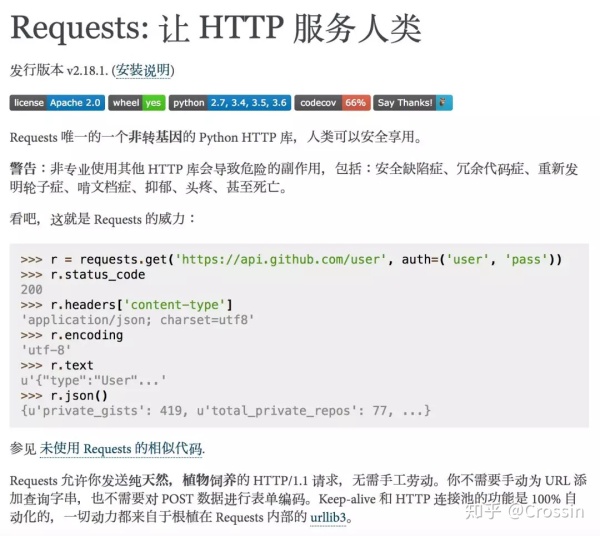
Requests 自我定义为 HTTP for Humans:让 HTTP 服务人类,或者说最人性化的 HTTP。言外之意,之前的那些 HTTP 库太过繁琐,都不是给人用的。(urllib 表示:怪我咯!)
尽管听上去有些自大,但实际上它的的确确配得上这个评价,用过的都说好。我在文首搬出它的网红作者,其实也仅仅是想吸引下你的眼球,然后告诉你,这真的是一个非常值得使用的库。“提升8倍”虽是我胡诌的数据,开发效率的提升却是杠杠滴。
我们先来看看它官网上的说法:
其他同样非常值得推荐的东西,如 PyCharm、Anaconda 等,我在推荐完之后往往得写上一些教程,并在后续不断解答使用者的问题。
而 Requests 却不同,它提供了官方中文文档,其中包括了很清晰的“快速上手”和详尽的高级用法和接口指南。以至于我觉得再把文档里面内容搬运过来都是一种浪费。对于 Requests,要做的仅仅是两件事:
告诉你有这样一个工具,用来开发爬虫很轻松告诉你它的官方文档很好,你去读就可以了
到此为止,本篇的目的已经达到。不过为了更有说服力,以及照顾到一些暂时还不需要但以后可能会去看的同学,我还是再啰嗦几句,演示下 Requests 的威力。安装
pip install requests 即可
请求网页
import requests
r = requests.get('http://httpbin.org/get')
print(r.status_code)
print(r.encoding)
print(r.text)
print(r.json())
复制代码
只需一行代码就可以完成 HTTP 请求。然后轻松获取状态码、编码、内容,甚至按 JSON 格式转换数据。虽然这种简单请求用别的库也不复杂,但其实在内部,Requests 已帮你完成了添加 headers、自动解压缩、自动解码等操作。写过课程中“查天气”的同学,很可能踩过 gzip 压缩的坑,用 Requests 就不存在了。如果你发现获取的内容编码不对,也只需要直接给 encoding 赋值正确的编码后再访问 text,就自动完成了编码转换,非常方便。
想要下载一张图片:
r = requests.get("https://www.baidu.com/img/bd_logo1.png")
with open('image.png', 'wb') as f:
f.write(r.content)
复制代码
把返回结果的 content 保存在文件里就行了。
提交一个 POST 请求,同时增加请求头、cookies、代理等信息(此处使用的代理地址不是真实的,测试代码时需去掉):
import requests
url = 'http://httpbin.org/post'
cookies = dict(some_cookie='working')
headers = {'user-agent': 'chrome'}
proxies = {
'http':'http://10.10.1.10:3128',
'https':'http://10.10.1.10:1080',
}
data = {'key1': 'value1', 'key2': 'value2'}
r = requests.get(
url,
data=data,
cookies=cookies,
proxies=proxies,
headers=headers
)
print(r.text)
复制代码
上述几个配置,如果使用自带的 urllib 库,代码要增加不少。
有时我们做爬虫时,需要保持 cookie 一致,比如登录后才可访问的页面。用 Session 会话对象就可以实现:
s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)
复制代码
另外提两个常见小问题:一个是关于 SSL,也就是 https 证书的问题。如果碰到 HTTPS 证书无效导致无法访问的错误,可以尝试加参数 verify=False 忽略:
r = requests.get('https://www.12306.cn/', verify=False)
print(r.text)
复制代码
另一个是对于设置了自动跳转的页面,默认会跟随跳转(但仅限于控制域名跳转,无法跟随 js 跳转),也可以加参数 allow_redirects=False 禁止:
r = requests.get('http://github.com/', allow_redirects=False)
print(r.status_code)
print(r.text)
复制代码
上面两个例子,把参数去掉试试看效果。
其他更多详细内容不多说了,中文官网地址
cn.python-requests.org
,顺着看一遍,写一遍,你就掌握这个爬虫神器了。
对了,作者今年又发布了个新的库
Requests-HTML: HTML Parsing for Humans
,用来对抓取到的 HTML 文本进行处理。这是要把 bs4 也一并干掉的节奏啊。现在更新到 0.9 版本,密切关注中。
我们编程教室的不少演示项目如 电影票价查询、就业岗位分析、IP 代理池 里也都使用了 Requests 库,想了解的请在公众号(Crossin的编程教室)里回复 项目
════其他文章及回答:
如何自学Python
|
新手引导
|
精选
Python
问答
|
Python单词表
|
区块链
|
人工智能
|
双11
|
嘻哈
|
爬虫
|
排序算法
|
我用Python
|
高考
|
世界杯
欢迎搜索及关注:Crossin的编程教室
2018-6-28 15:48 上传
下载附件
(15.37 KB)
欢迎光临 Crossin的编程教室 (https://bbs.crossincode.com/)
Powered by Discuz! X2.5