- 帖子
- 176
- 精华
- 1
- 积分
- 733
- 阅读权限
- 100
- 注册时间
- 2013-8-21
- 最后登录
- 2020-12-20
  
|
 发表于 2018-11-1 16:42:35
|显示全部楼层
发表于 2018-11-1 16:42:35
|显示全部楼层
如今说到体感游戏,大家一定都不陌生,比如微软的 Kinect、任天堂的 Switch,都曾是游戏业的革命性产品。而另一款网红产品—抖音,也在去年底上线过一个“尬舞机”的音乐体感游戏(现在成了隐藏功能):

游戏开始后,随着音乐会给出不同的动作提示,用户按照提示摆出正确动作即可得分。援引官方说法,“尬舞机”主要应用了今日头条 AI Lab 自主开发的“人体关键点检测技术”,依靠这项技术,抖音能够检测到图像中所包含人体的各个关键点的位置,从而实现从用户姿态到目标姿态的准确匹配。
以上这些体感游戏,都牵涉到计算机视觉中的一个细分领域:人体姿态估计(pose estimation),即识别图像中的人体关键点(人体上有一定自由度的关节,如头、颈、肩、肘、腕、腰、膝、踝等)并正确的联系起来,通过对人体关键点在三维空间相对位置的计算,来估计人体当前的姿态。
人体姿态估计有不少难点,比如:如何从图片中区分出人和背景;如何定位人体的关键点;如何根据二维的关键点坐标计算出三维中的姿态;如何处理四肢交叉或遮挡的情况;如何定位多人;如何提升计算速度等等。而相关技术在游戏、安防、人机交互、行为分析等方面都有应用前景。因此,这是计算机视觉甚至人工智能领域中极具挑战的一个课题。(小声说句,我的硕士毕业论文就是这个方向)
不过,因为前人的贡献,现在你只需通过少量的 Python 代码,也可以实现从照片或视频中进行人体姿态估计。这都要仰赖于 CMU 的开源项目:Openpose。
OpenPose 是基于卷积神经网络和监督学习并以 caffe 为框架写成的开源库,可以实现人的面部表情、躯干和四肢甚至手指的跟踪,适用多人且具有较好的鲁棒性。是世界上第一个基于深度学习的实时多人二维姿态估计,为机器理解人类提供了一个高质量的信息维度。其理论基础来自《Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields》,是 CVPR 2017 的一篇论文,作者是来自 CMU 感知计算实验室的曹哲、Tomas Simon、Shih-En Wei、Yaser Sheikh。项目地址: https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation(摘自网络)
论文演示效果:
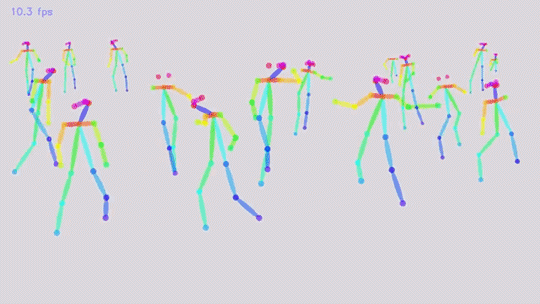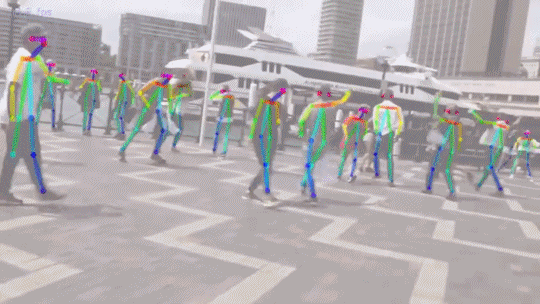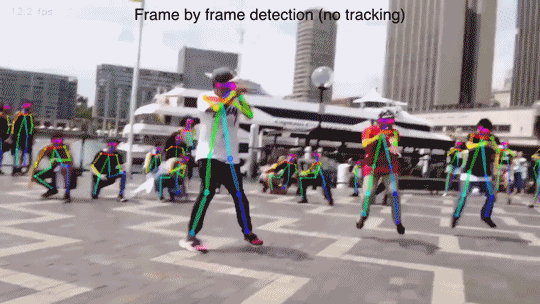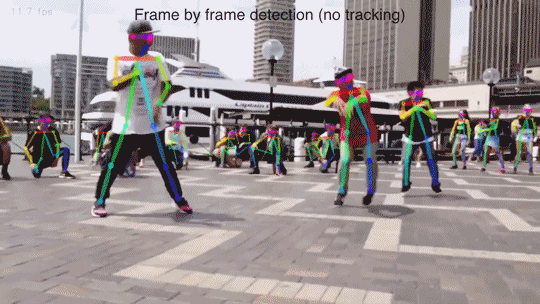
此方法可以达到对视频流的实时多人检测。要知道,Kinect 可是加了一个额外的红外深度摄像头才做到如此准确地识别(还不能是这么多人)。
详细的原理,我在这里就不冒充大牛强行解释了。但通俗地说几点,为什么 Openpose 有如此突破性地效果:
以往的识别思路是自上而下:先找人,找到人了再进一步区分身体不同部分。Openpose 则是自下而上:先找手脚关节等特征部位,再组合人体;Openpose 团队将人脸识别、手部识别的已有成果整合到了姿态识别中,取得了更好的效果;有了大数据的支持,这是过去的研究所没有的。看看这个 CMU 为采集人体数据所搭建的设备,你就会有所体会: 
之前的文章 Python+OpenCV 十几行代码模仿世界名画 中,我们提到 OpenCV-Python 在 3.3 版本中加入了深度神经网络(DNN)的支持。同样在项目 Samples 中,提供 Openpose 的一个 Python 简单实现版本。(只支持图像中有单个人)
官方代码:
https://github.com/opencv/opencv/blob/master/samples/dnn/openpose.py
使用方法,命令行进入代码所在目录执行:- python openpose.py --model pose.caffemodel --proto pose.prototxt --dataset MPI
另外可以通过 --input 参数指定识别的图片或视频地址,默认则使用摄像头实时采集。
执行后效果:
 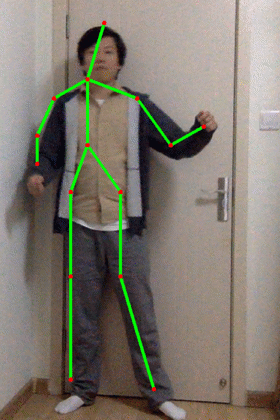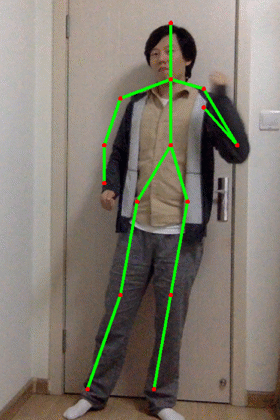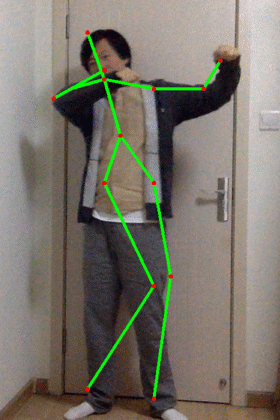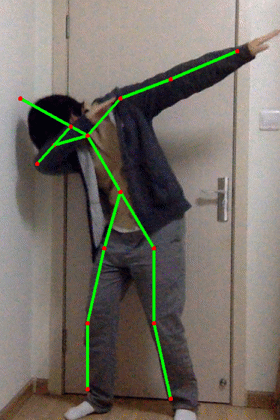
核心代码:- net = cv.dnn.readNetFromCaffe(args.proto, args.model)
- inp = cv.dnn.blobFromImage(frame, 1.0 / 255, (inWidth, inHeight), (0, 0, 0), swapRB=False, crop=False)
- net.setInput(inp)
- out = net.forward()
这里顺带提醒一下,我发现代码中的一个断言 assert(len(BODY_PARTS) == out.shape[1]) 无法满足,会导致程序终止。如果出现这样的问题,就把这句注释掉,并不会对结果有影响。
拿到人体关键点数据后,我们就可以做进一步的判断。比如我们加一个很简单的判断:- neck = points[BODY_PARTS['Neck']]
- left_wrist = points[BODY_PARTS['LWrist']]
- right_wrist = points[BODY_PARTS['RWrist']]
- print(neck, left_wrist, right_wrist)if neck and left_wrist and right_wrist and left_wrist[1] < neck[1] and right_wrist[1] < neck[1]:
- cv.putText(frame, 'HANDS UP!', (10, 100), cv.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 2)
效果:
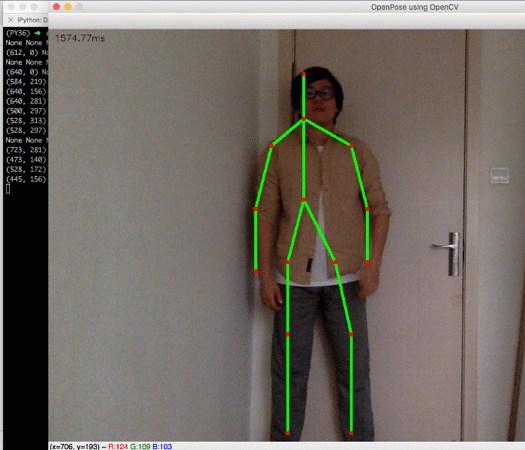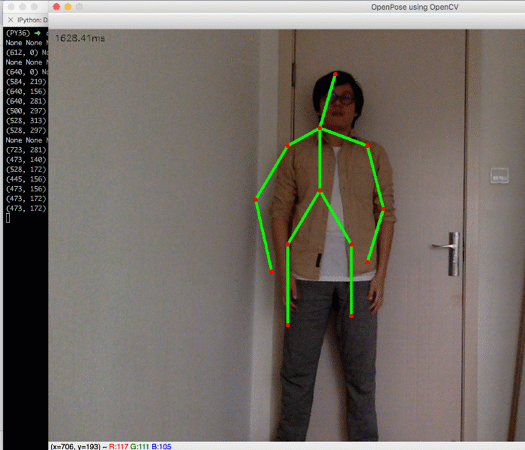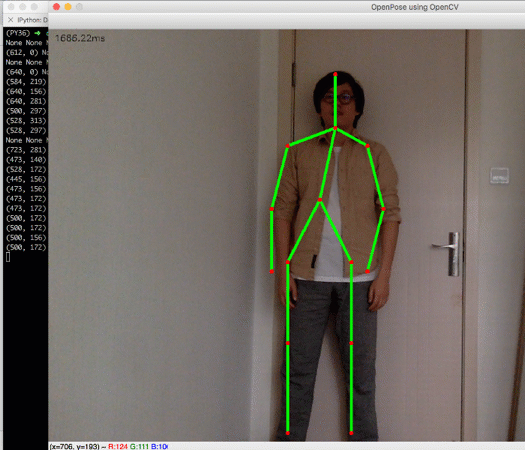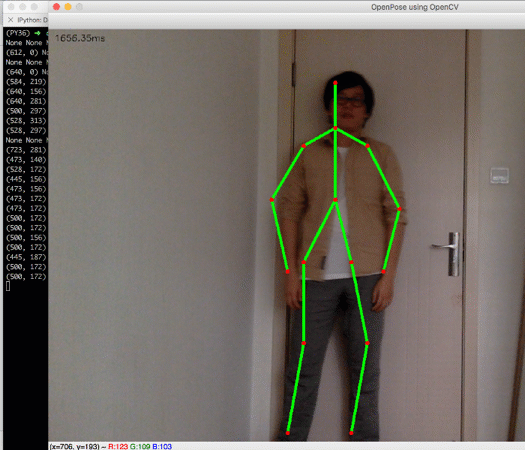
如此,一个简单的动作识别程序就有了。虽然很粗糙,但已经可以附加在很多应用上,比如:商场、科技馆里的互动游戏、交互式的视觉艺术作品等等。感兴趣的同学不妨亲自试一试,期待看到你们借此做出更有意思的项目。
获取文中相关代码和模型下载地址,请在公众号(Crossin的编程教室)对话里回复关键字 姿态
════其他文章及回答:
如何自学Python | 新手引导 | 精选Python问答 | 如何debug? | Python单词表 | 知乎下载器 | 人工智能 | 嘻哈 | 爬虫 | 我用Python | 抓抖音 | requests | AI平台 | AI名画
欢迎微信搜索及关注:Crossin的编程教室
 |
|
 |手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 )
|手机版|Archiver|Crossin的编程教室
( 苏ICP备15063769号 ) 




 发表于 2019-8-5 18:13:21
发表于 2019-8-5 18:13:21